13 KiB
Python 实现基于 RAG 的记忆存储 MCP 服务器
前言
本篇教程,我们将演示如何使用 Python 构建一个简易的基于 RAG (Retrieval-Augmented Generation) 的长期记忆存储 MCP 服务器, 并通过 openmcp 插件进行调试。 实现完成后,我们能够通过与大模型进行自然语言交互,轻松地存储、检索和管理我们的记忆,而无需编写任何特定的查询代码。
1. 准备
项目结构如下:
📦rag_memo_mcp
┣ 📂memory_db/ # LanceDB 数据库文件,初始化时会创建
┣ 📜server.py # MCP 服务器实现
┣ 📜pyproject.toml # 项目配置文件
┣ 📜uv.lock # uv lockfile
┗ ...
首先,我们来准备运行环境。本项目推荐使用 uv。(uv 是一个速度快得飞起的 Python 包管理器,用过都说好。当然,如果你是 pip 或者其他包管理器的忠实粉丝,也完全没问题)
# 首先下载 uv (Windows)
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
# 或者 (macOS/Linux)
# curl -LsSf https://astral.sh/uv/install.sh | sh
# 项目初始化
uv init rag_memo_mcp
cd rag_memo_mcp
# 建议创建一个虚拟环境
uv venv
# 激活虚拟环境 (Windows)
.venv\Scripts\activate
# 或者 (macOS/Linux)
# source .venv/bin/activate
# 安装依赖
uv add "mcp[cli]" lancedb pandas sentence-transformers
2. 理解服务实现
与需要预先安装和配置的传统数据库不同,本项目的核心 MemoryStore 使用 LanceDB,这是一个向量数据库,它会在服务器首次启动时自动在 memory_db 目录下创建并初始化,无需额外配置。
让我们深入 server.py 来理解其实现细节。
2.1 MemoryStore 核心类
MemoryStore 类是记忆存储和检索功能的核心。
class MemoryStore:
initialize(): 这个方法负责初始化。它会连接到 LanceDB 数据库(如果不存在则创建),定义记忆表的 schema,并默认加载all-MiniLM-L6-v2用于将文本内容生成向量嵌入。
def __init__(self, db_path: str = "./memory_db"):
self.db_path = db_path
self.db = None
self.table = None
self.encoder = None
self._initialized = False
async def initialize(self):
if self._initialized:
return
self.encoder = SentenceTransformer("all-MiniLM-L6-v2")
self.db = lancedb.connect(self.db_path)
schema = pa.schema(
[
pa.field("id", pa.string()),
pa.field("content", pa.string()),
pa.field("summary", pa.string()),
pa.field("tags", pa.list_(pa.string())),
pa.field("timestamp", pa.timestamp("us")),
pa.field("category", pa.string()),
pa.field("importance", pa.int32()),
pa.field(
"vector", pa.list_(pa.float32(), 384)
),
]
)
try:
self.table = self.db.open_table("memories")
except Exception:
self.table = self.db.create_table("memories", schema=schema)
self._initialized = True
store_memory(): 当需要存储一条新记忆时,此方法会被调用。它会为记忆内容生成一个唯一的ID和时间戳,如果未提供摘要,则自动生成一个简单的摘要,然后使用预加载的模型将内容转换为向量,最后将所有信息(ID, 内容, 摘要, 标签, 时间戳, 类别, 重要性, 向量)存入 LanceDB 表中。
async def store_memory(
self,
content: str,
summary: Optional[str] = None,
tags: Optional[List[str]] = None,
category: str = "general",
importance: int = 5,
) -> str:
await self.initialize()
memory_id = str(uuid.uuid4())
timestamp = datetime.now(timezone.utc)
if not summary:
summary = content[:100] + "..." if len(content) > 100 else content
embedding = self._generate_embedding(content)
data = [
{
"id": memory_id,
"content": content,
"summary": summary,
"tags": tags or [],
"timestamp": timestamp,
"category": category,
"importance": importance,
"vector": embedding,
}
]
self.table.add(data)
return memory_id
search_memories(): 这是实现 RAG 的关键。当提出一个查询时,此方法会将查询文本同样转换为向量,然后在 LanceDB 中执行向量相似度搜索,以找到最相关的记忆。它还支持按类别和重要性进行过滤。
async def search_memories(
self,
query: str,
limit: int = 10,
category: Optional[str] = None,
min_importance: Optional[int] = None,
) -> List[Dict[str, Any]]:
await self.initialize()
query_embedding = self._generate_embedding(query)
search_query = self.table.search(query_embedding)
if limit:
search_query = search_query.limit(limit)
filters = []
if category:
filters.append(f"category = '{category}'")
if min_importance is not None:
filters.append(f"importance >= {min_importance}")
if filters:
filter_str = " AND ".join(filters)
search_query = search_query.where(filter_str)
results = search_query.to_pandas()
memories = []
for _, row in results.iterrows():
memory = {
"id": row["id"],
"content": row["content"],
"summary": row["summary"],
"tags": row["tags"].tolist(),
"timestamp": row["timestamp"],
"category": row["category"],
"importance": int(row["importance"]),
"similarity_score": row.get(
"_distance", 0.0
),
}
memories.append(memory)
return memories
2.2 MCP 服务器与工具
我们使用 FastMCP 来快速构建一个 MCP 服务器,并通过 @mcp.tool() 装饰器将 MemoryStore 的功能暴露为大模型可以调用的工具。
store_memory: 记笔记! 存储一条记忆。search_memories: 让我想想... 根据查询内容搜索相关记忆。get_memory: 按图索骥! 根据 ID 精确检索某条记忆。list_categories: 分门别类! 列出所有记忆的分类。get_memory_stats: 记忆盘点! 获取关于记忆库的统计信息,如总数、各分类数量等。
# 初始化记忆存储
memory_store = MemoryStore()
# 创建 MCP 服务器
mcp = FastMCP("RAG-based Memory MCP Server")
@mcp.tool()
async def store_memory(
content: str,
summary: Optional[str] = None,
tags: Optional[str] = None,
category: str = "general",
importance: int = 5,
) -> Dict[str, str]:
"""
Store content in memory.
Args:
content: The content to store
summary: Optional summary (auto-generated if not provided)
tags: Comma-separated tags
category: Memory category (default: general)
importance: Importance level 1-10 (default: 5)
"""
try:
# Parse tags if provided
tag_list = [tag.strip() for tag in tags.split(",")] if tags else []
memory_id = await memory_store.store_memory(
content=content,
summary=summary,
tags=tag_list,
category=category,
importance=importance,
)
return {
"status": "success",
"memory_id": memory_id,
"message": f"Memory stored successfully with ID: {memory_id}",
}
except Exception as e:
return {"status": "error", "message": f"Failed to store memory: {str(e)}"}
@mcp.tool()
async def search_memories(
query: str,
limit: int = 10,
category: Optional[str] = None,
min_importance: Optional[int] = None,
) -> Dict[str, Any]:
"""
Search stored memories using semantic similarity.
Args:
query: Search query
limit: Maximum number of results (default: 10)
category: Filter by category
min_importance: Minimum importance level
"""
try:
memories = await memory_store.search_memories(
query=query, limit=limit, category=category, min_importance=min_importance
)
return {
"status": "success",
"query": query,
"total_results": len(memories),
"memories": memories,
}
except Exception as e:
return {"status": "error", "message": f"Search failed: {str(e)}"}
@mcp.tool()
async def get_memory(memory_id: str) -> Dict[str, Any]:
"""
Retrieve a specific memory by its ID.
Args:
memory_id: The unique identifier of the memory
"""
try:
memory = await memory_store.get_memory_by_id(memory_id)
if memory:
return {"status": "success", "memory": memory}
else:
return {
"status": "error",
"message": f"Memory with ID {memory_id} not found",
}
except Exception as e:
return {"status": "error", "message": f"Failed to retrieve memory: {str(e)}"}
@mcp.tool()
async def list_categories() -> Dict[str, Any]:
try:
categories = await memory_store.list_categories()
return {"status": "success", "categories": categories}
except Exception as e:
return {"status": "error", "message": f"Failed to list categories: {str(e)}"}
@mcp.tool()
async def get_memory_stats() -> Dict[str, Any]:
try:
stats = await memory_store.get_stats()
return {"status": "success", "stats": stats}
except Exception as e:
return {"status": "error", "message": f"Failed to get stats: {str(e)}"}
服务器的启动代码位于 server.py 的末尾,它首先初始化 MemoryStore,然后运行 MCP 服务器。
if __name__ == "__main__":
# 在启动时初始化记忆存储
async def init_memory():
await memory_store.initialize()
# 运行初始化
asyncio.run(init_memory())
# 运行 MCP 服务器
mcp.run()
3. 通过 openmcp 来进行调试
3.1 添加工作区连接
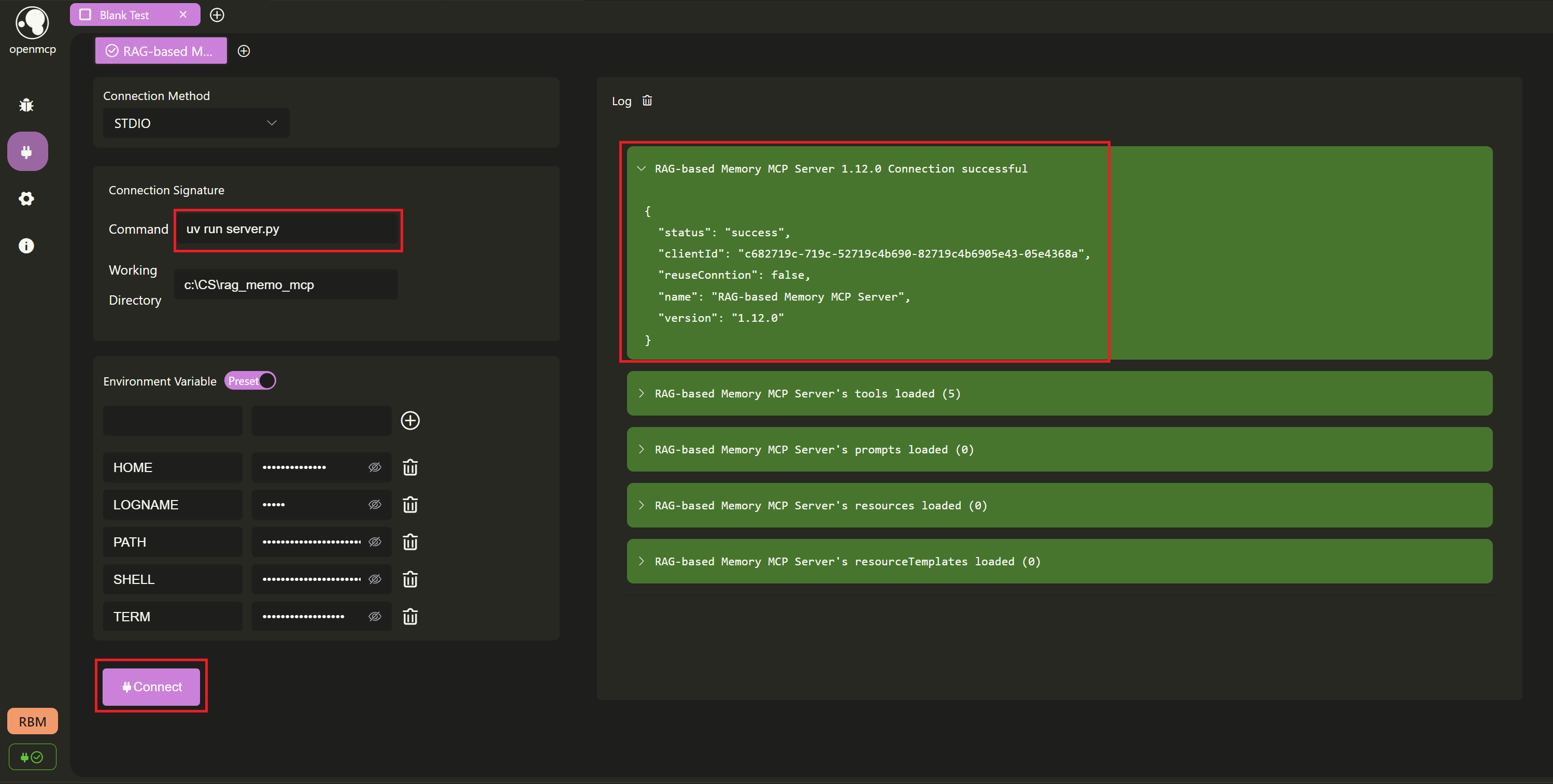
接下来,我们通过 openmcp 插件进行调试。首先测试是否能连接成功,这里选择 stdio,工作路径设置为项目所在的目录,然后点击 Connect。右边的日志栏里可以看到我们已经连接成功。
3.2 测试工具
连接成功后,让我们先测试一下工具是否工作正常。
-
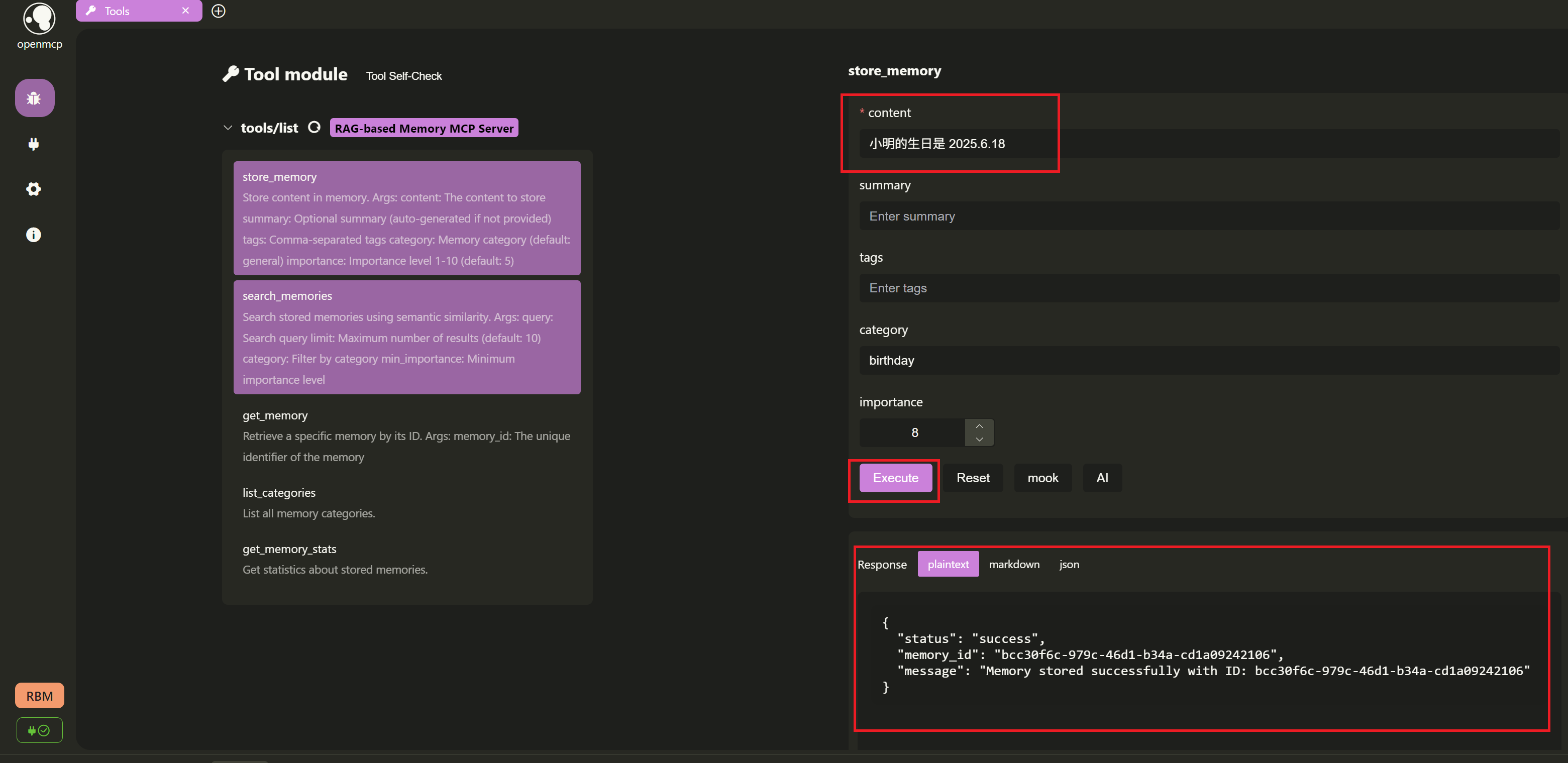
存个小秘密: 新建一个
Tool标签页,选择store_memory工具。例如我们输入:content:小明的生日是 2025.6.18category:birthdayimportance:8
点击
Execute,如果成功会返回存储的记忆 ID,比如这里返回bcc30f6c-979c-46d1-b34a-cd1a09242106
-
根据 ID 精确检索某条记忆: 存储成功后,我们根据返回的记忆 ID
bcc30f6c-979c-46d1-b34a-cd1a09242106,选择get_memory工具,测试是否能够从Lancedb里面检索出来。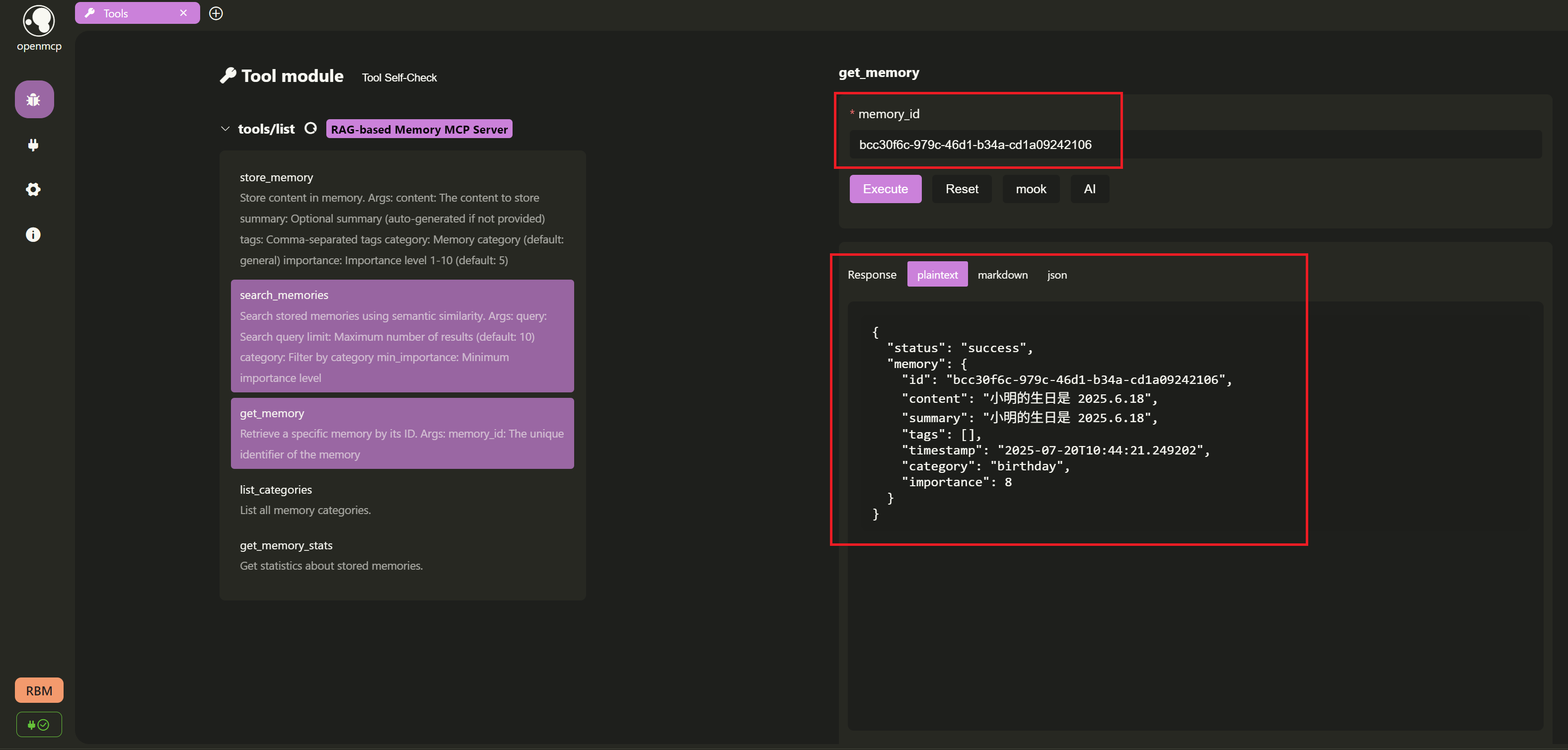
-
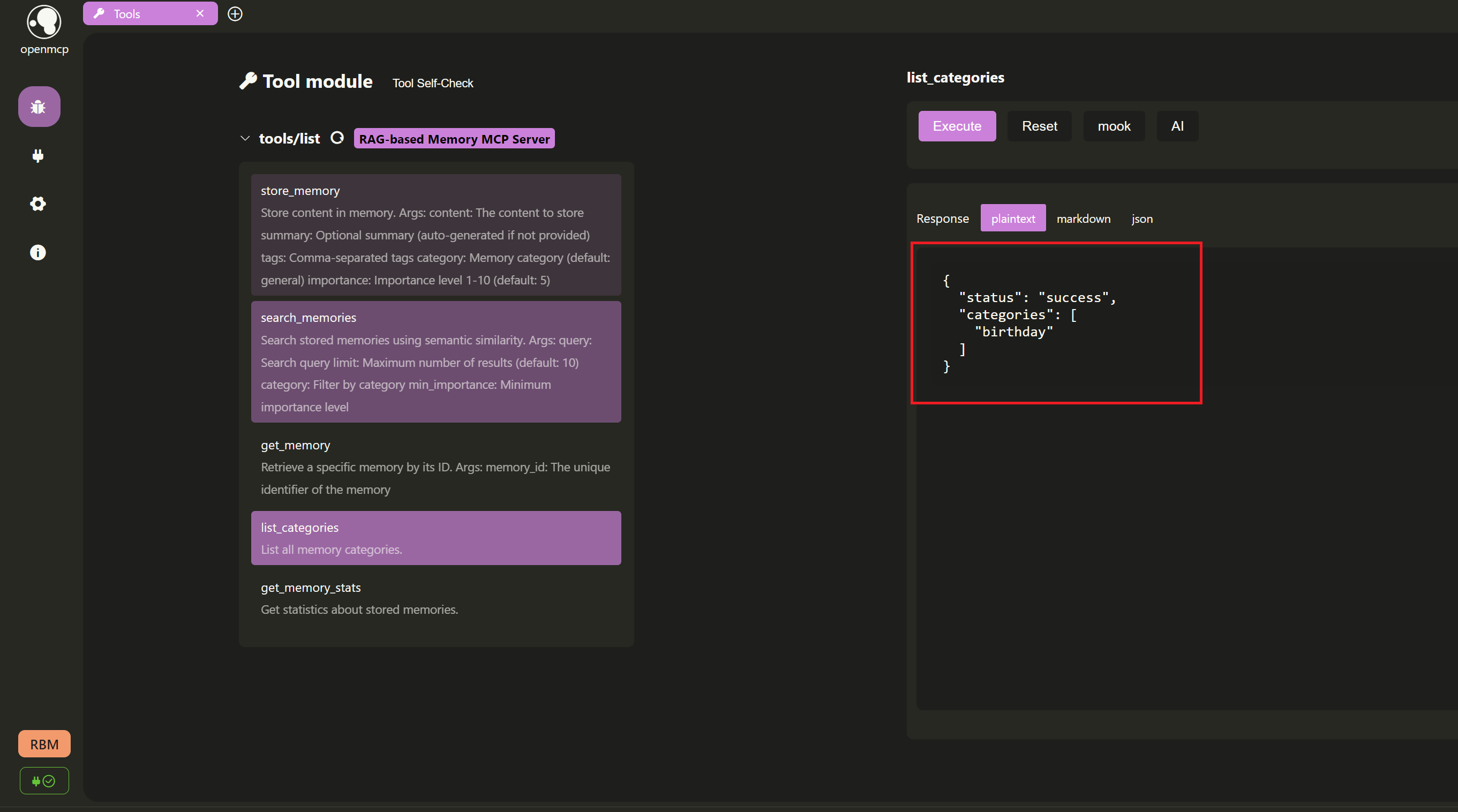
列出目前的记忆分类: 我们调用
list_categories工具来查看当前所有记忆的分类。由于我们只添加了一个birthday分类的记忆,所以返回结果中应该只包含这个分类。
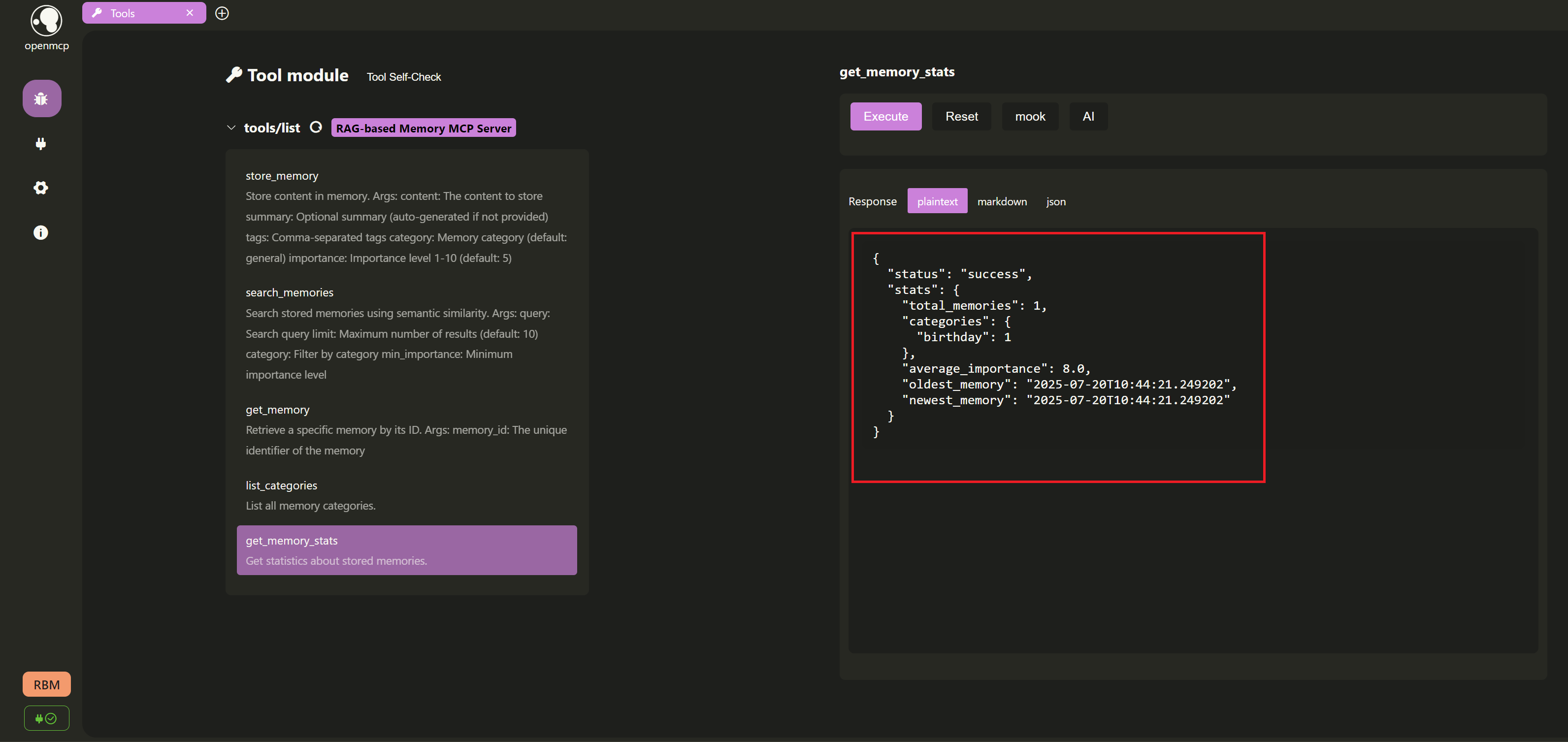
- 获取记忆统计数据:
接着,我们使用
get_memory_stats工具来获取记忆库的统计信息,例如总共有多少条记忆,以及每个分类下的记忆数量。
3.3 大模型交互测试
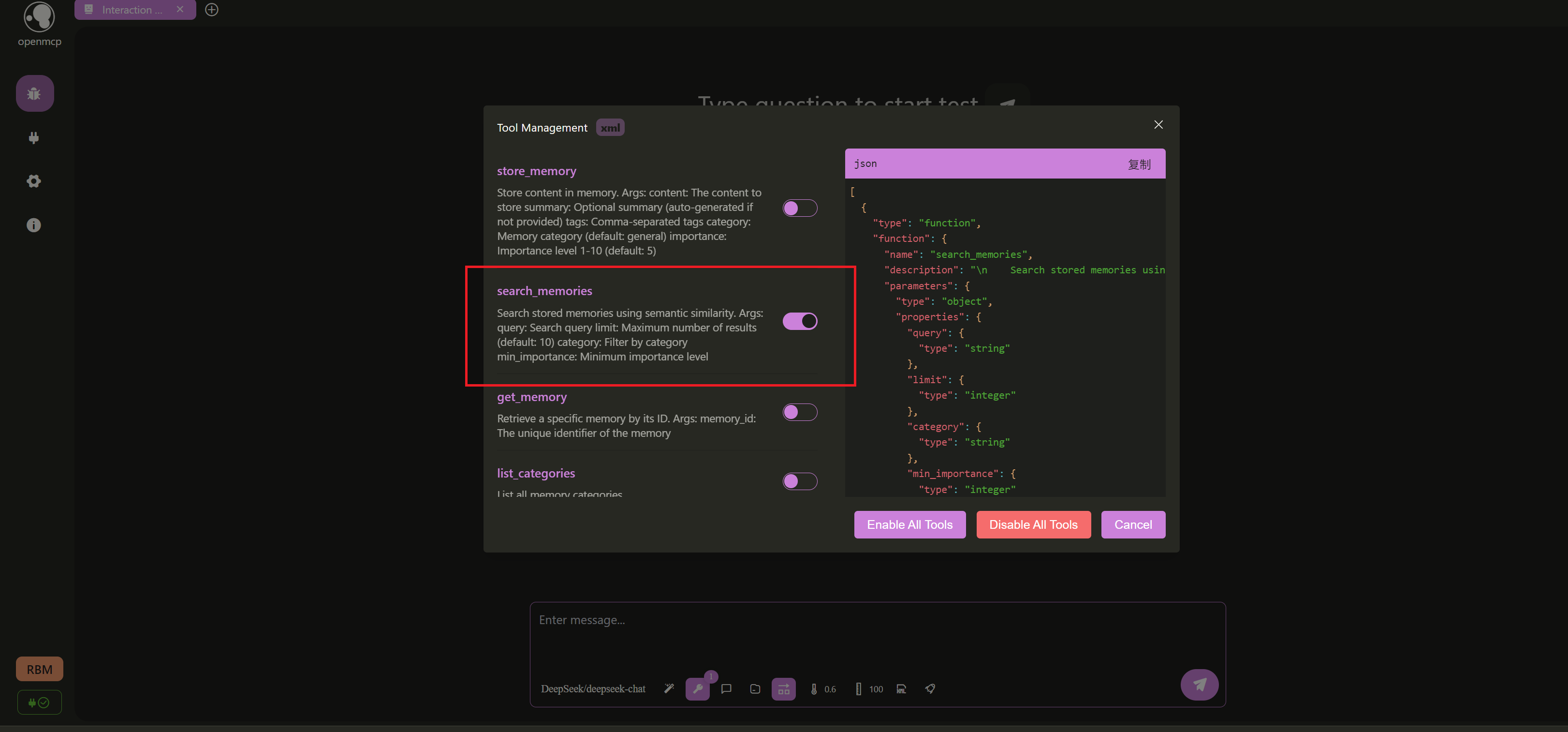
上面我们"遗漏"了一个工具 search_memories 没有测试,其实是特意把它留给了大模型交互测试。进入交互测试页面(记得事先参照连接大模型教程设置好大模型的 api_key 和 base_url),我们可以先把其他的工具都取消配备,只保留 search_memories 这一个工具:
然后,我们假装不经意地问一句:
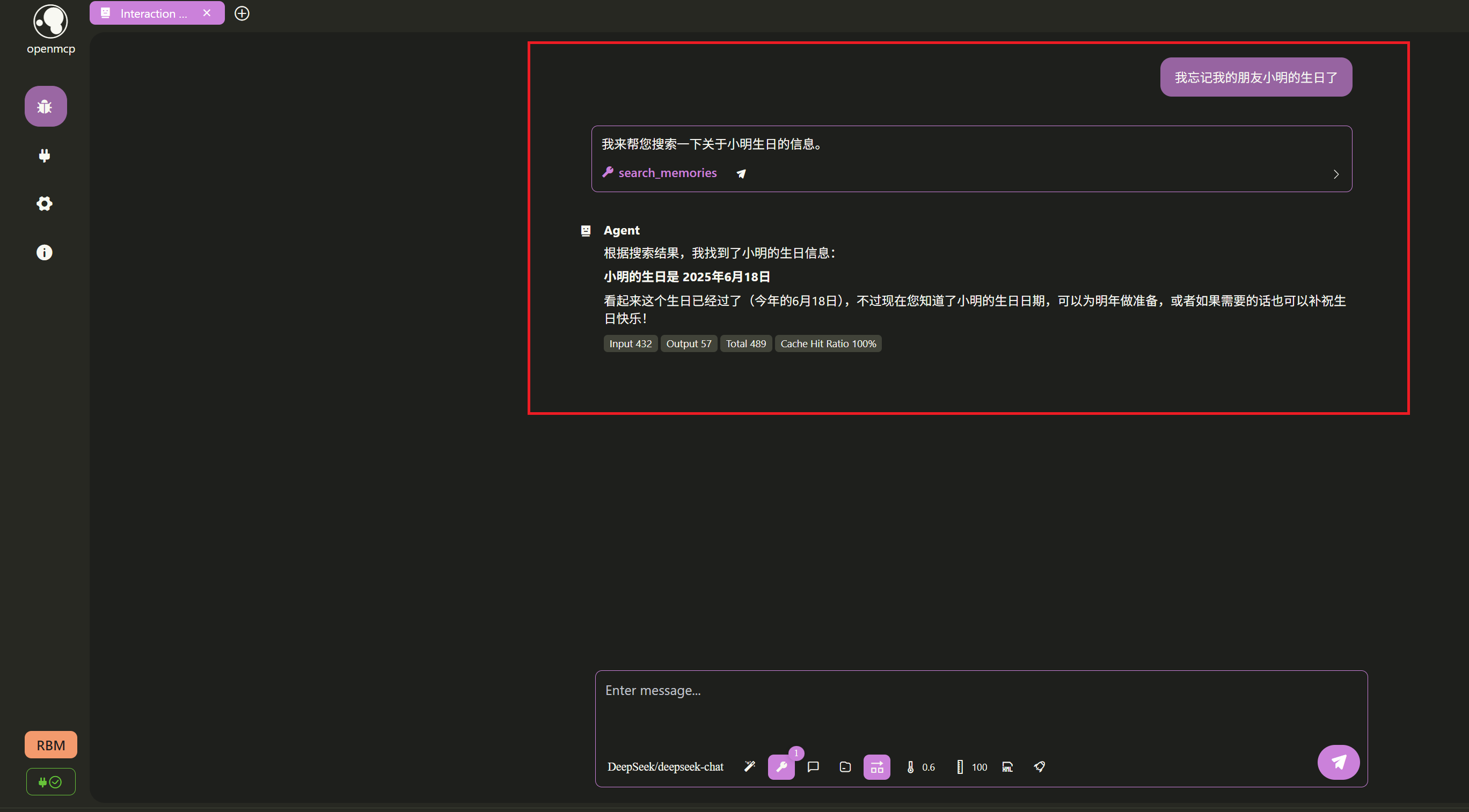
好! 大模型成功帮助我召回了我的朋友小明的生日, Cheers!