18 KiB
go 实现 neo4j 的只读 mcp 服务器 (SSE)
前言
本篇教程,演示一下如何使用 go 语言写一个可以访问 neo4j 数据库的 mcp 服务器。实现完成后,我们不需要写任何 查询代码 就能通过询问大模型了解服务器近况。
不同于之前的连接方式,这次,我们将采用 SSE 的方式来完成服务器的创建和连接。
本期教程的代码:https://github.com/LSTM-Kirigaya/openmcp-tutorial/tree/main/neo4j-go-server
建议下载本期的代码,因为里面有我为大家准备好的数据库文件。要不然,你们得自己 mock 数据了。
1. 准备
项目结构如下:
📦neo4j-go-server
┣ 📂util
┃ ┗ 📜util.go # 工具函数
┣ 📜main.go # 主函数
┗ 📜neo4j.json # 数据库连接的账号密码
我们先创建一个 go 项目:
mkdir neo4j-go-server
cd neo4j-go-server
go mod init neo4j-go-server
2. 完成数据库初始化
2.1 安装 neo4j
首先,根据我的教程在本地或者服务器配置一个 neo4j 数据库,这里是是教程,你只需要完成该教程的前两步即可: neo4j 数据库安装与配置。将 bin 路径加入环境变量,并且设置的密码设置为 openmcp。
然后在 main.go 同级下创建 neo4j.json,填写 neo4j 数据库的连接信息:
{
"url" : "neo4j://localhost:7687",
"name" : "neo4j",
"password" : "openmcp"
}
2.2 导入事先准备好的数据
安装完成后,大家可以导入我实现准备好的数据,这些数据是我的个人网站上部分数据脱敏后的摘要,大家可以随便使用,下载链接:neo4j.db。下载完成后,运行下面的命令:
neo4j stop
neo4j-admin load --database neo4j --from neo4j.db --force
neo4j start
然后,我们登录数据库就能看到我准备好的数据啦:
cypher-shell -a localhost -u neo4j -p openmcp
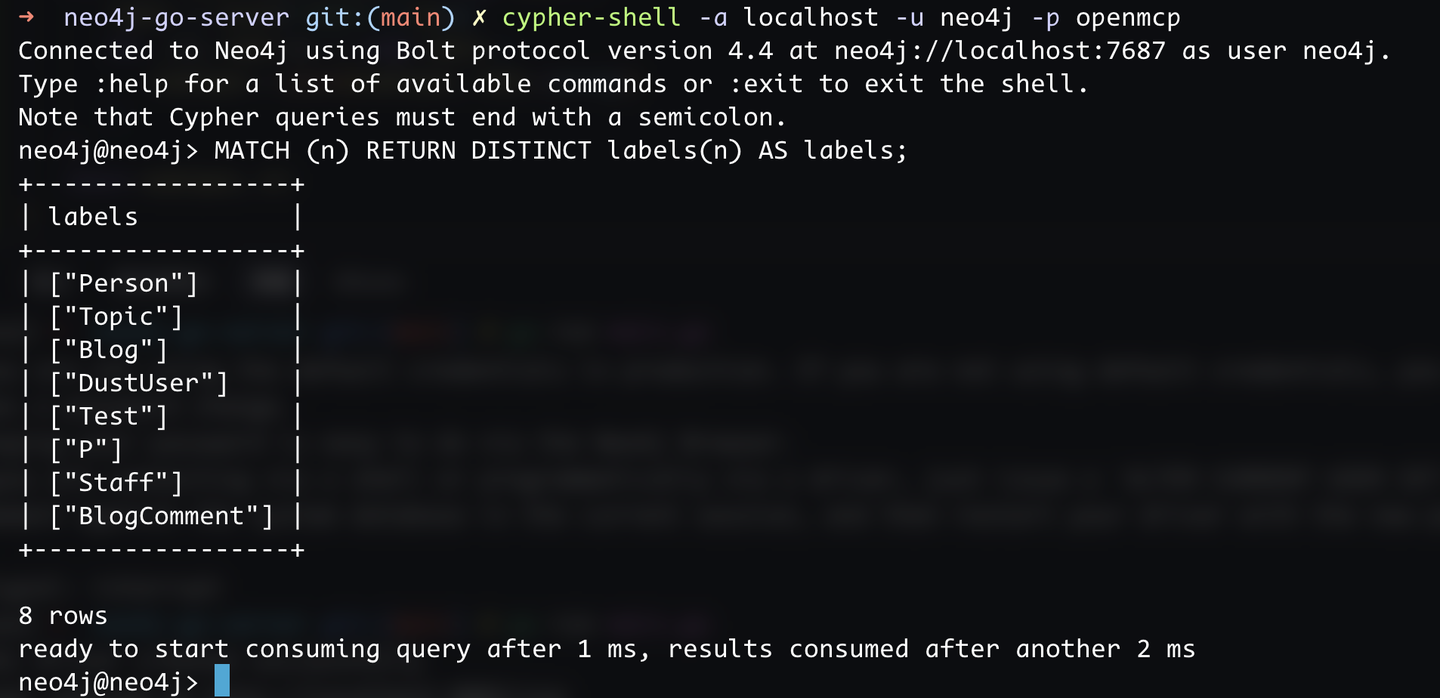
2.3 验证 go -> 数据库连通性
为了验证数据库的连通性和 go 的数据库驱动是否正常工作,我们需要先写一段数据库访问的最小系统。
先安装 neo4j 的 v5 版本的 go 驱动:
go get github.com/neo4j/neo4j-go-driver/v5
在 util.go 中添加以下代码:
package util
import (
"context"
"encoding/json"
"fmt"
"os"
"github.com/neo4j/neo4j-go-driver/v5/neo4j"
)
var (
Neo4jDriver neo4j.DriverWithContext
)
// 创建 neo4j 服务器的连接
func CreateNeo4jDriver(configPath string) (neo4j.DriverWithContext, error) {
jsonString, _ := os.ReadFile(configPath)
config := make(map[string]string)
json.Unmarshal(jsonString, &config)
// fmt.Printf("url: %s\nname: %s\npassword: %s\n", config["url"], config["name"], config["password"])
var err error
Neo4jDriver, err = neo4j.NewDriverWithContext(
config["url"],
neo4j.BasicAuth(config["name"], config["password"], ""),
)
if err != nil {
return Neo4jDriver, err
}
return Neo4jDriver, nil
}
// 执行只读的 cypher 查询
func ExecuteReadOnlyCypherQuery(
cypher string,
) ([]map[string]any, error) {
session := Neo4jDriver.NewSession(context.TODO(), neo4j.SessionConfig{
AccessMode: neo4j.AccessModeRead,
})
defer session.Close(context.TODO())
result, err := session.Run(context.TODO(), cypher, nil)
if err != nil {
fmt.Println(err.Error())
return nil, err
}
var records []map[string]any
for result.Next(context.TODO()) {
records = append(records, result.Record().AsMap())
}
return records, nil
}
main.go 中添加以下代码:
package main
import (
"fmt"
"github.com/neo4j/neo4j-go-driver/v5/neo4j"
"neo4j-go-server/util"
)
var (
neo4jPath string = "./neo4j.json"
)
func main() {
_, err := util.CreateNeo4jDriver(neo4jPath)
if err != nil {
fmt.Println(err)
return
}
fmt.Println("Neo4j driver created successfully")
}
运行主程序来验证数据库的连通性:
go run main.go
如果输出了 Neo4j driver created successfully,则说明数据库的连通性验证通过。
3. 实现 mcp 服务器
go 的 mcp 的 sdk 最为有名的是 mark3labs/mcp-go 了,我们就用这个。
mark3labs/mcp-go 的 demo 在 https://github.com/mark3labs/mcp-go,非常简单,此处直接使用即可。
先安装
go get github.com/mark3labs/mcp-go
然后在 main.go 中添加以下代码:
// ... existing code ...
var (
addr string = "localhost:8083"
)
func main() {
// ... existing code ...
s := server.NewMCPServer(
"只读 Neo4j 服务器",
"0.0.1",
server.WithToolCapabilities(true),
)
srv := server.NewSSEServer(s)
// 定义 executeReadOnlyCypherQuery 这个工具的 schema
executeReadOnlyCypherQuery := mcp.NewTool("executeReadOnlyCypherQuery",
mcp.WithDescription("执行只读的 Cypher 查询"),
mcp.WithString("cypher",
mcp.Required(),
mcp.Description("Cypher 查询语句,必须是只读的"),
),
)
// 将真实函数和申明的 schema 绑定
s.AddTool(executeReadOnlyCypherQuery, func(ctx context.Context, request mcp.CallToolRequest) (*mcp.CallToolResult, error) {
cypher := request.Params.Arguments["cypher"].(string)
result, err := util.ExecuteReadOnlyCypherQuery(cypher)
fmt.Println(result)
if err != nil {
return mcp.NewToolResultText(""), err
}
return mcp.NewToolResultText(fmt.Sprintf("%v", result)), nil
})
// 在 http://localhost:8083/sse 开启服务
fmt.Printf("Server started at http://%s/sse\n", addr)
srv.Start(addr)
}
go run main.go 运行上面的代码,你就能看到如下信息:
Neo4j driver created successfully
Server started at http://localhost:8083/sse
说明我们的 mcp 服务器在本地的 8083 上启动了。
4. 通过 openmcp 来进行调试
4.1 添加工作区 sse 调试项目
接下来,我们来通过 openmcp 进行调试,先点击 vscode 左侧的 openmcp 图标进入控制面板,如果你是下载的 https://github.com/LSTM-Kirigaya/openmcp-tutorial/tree/main/neo4j-go-server 这个项目,那么你能看到【MCP 连接(工作区)】里面已经有一个创建好的调试项目【只读 Neo4j 服务器】了。如果你是完全自己做的这个项目,可以通过下面的按钮添加连接,选择 sse 后填入 http://localhost:8083/sse,oauth 空着不填即可。
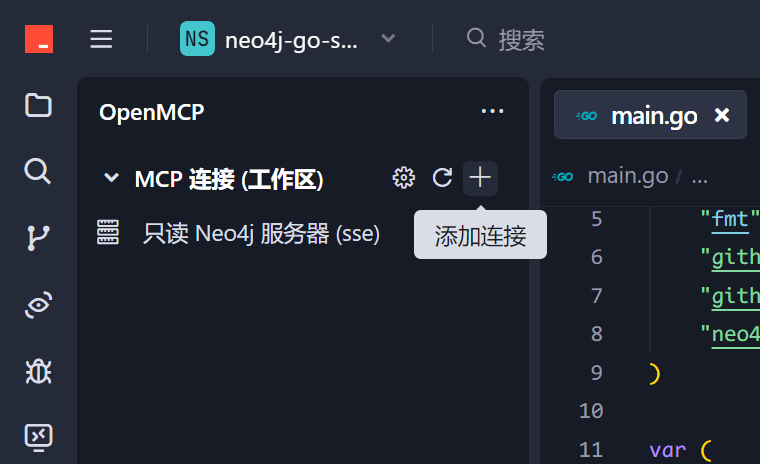
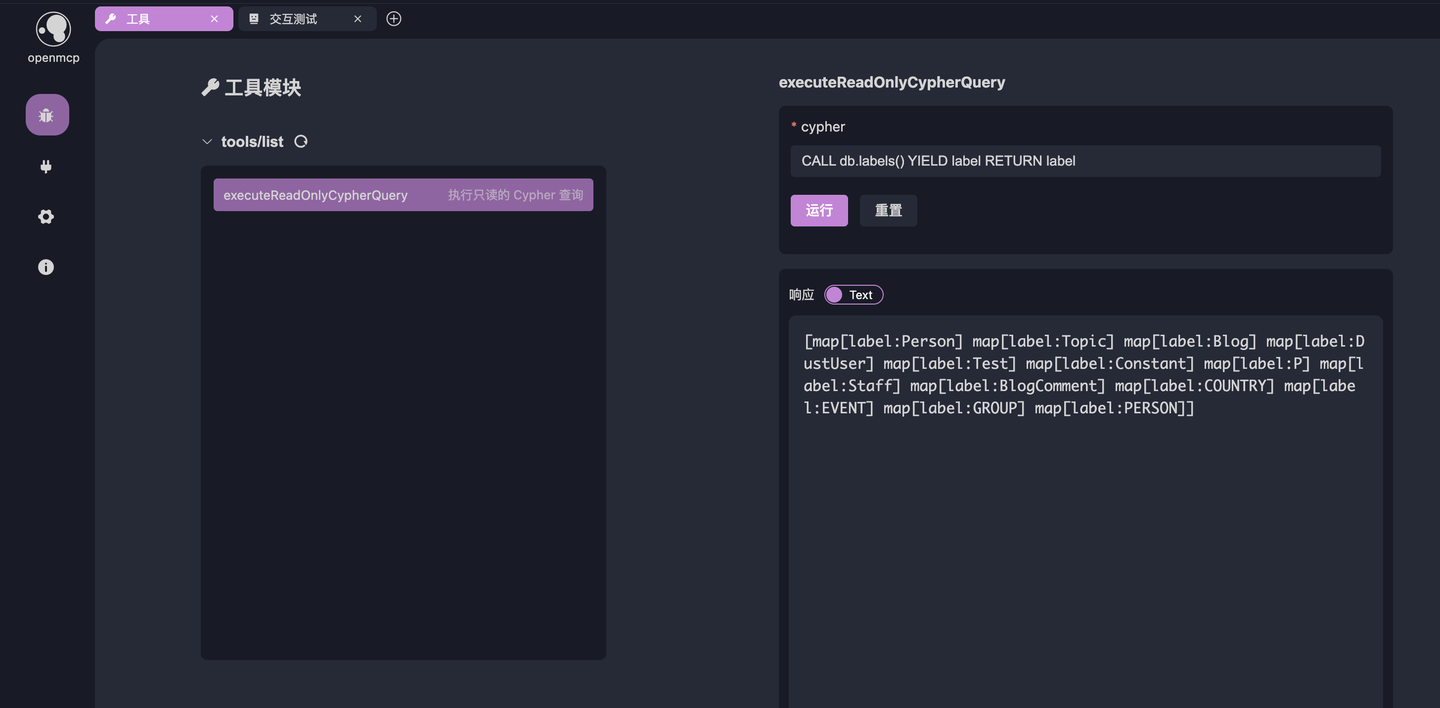
4.2 测试工具
第一次调试 mcp 服务器要做的事情一定是先调通 mcp tool,新建标签页,选择 tool,点击下图的工具,输入 CALL db.labels() YIELD label RETURN label,这个语句是用来列出所有节点类型的。如果输出下面的结果,说明当前的链路生效,没有问题。
4.3 摸清大模型功能边界,用提示词来封装我们的知识
然后,让我们做点有趣的事情吧!我们接下来要测试一下大模型的能力边界,因为 neo4j 属于特种数据库,通用大模型不一定知道怎么用它。新建标签页,点击「交互测试」,我们先问一个简单的问题:
帮我找出最新的 10 条评论
结果如下:
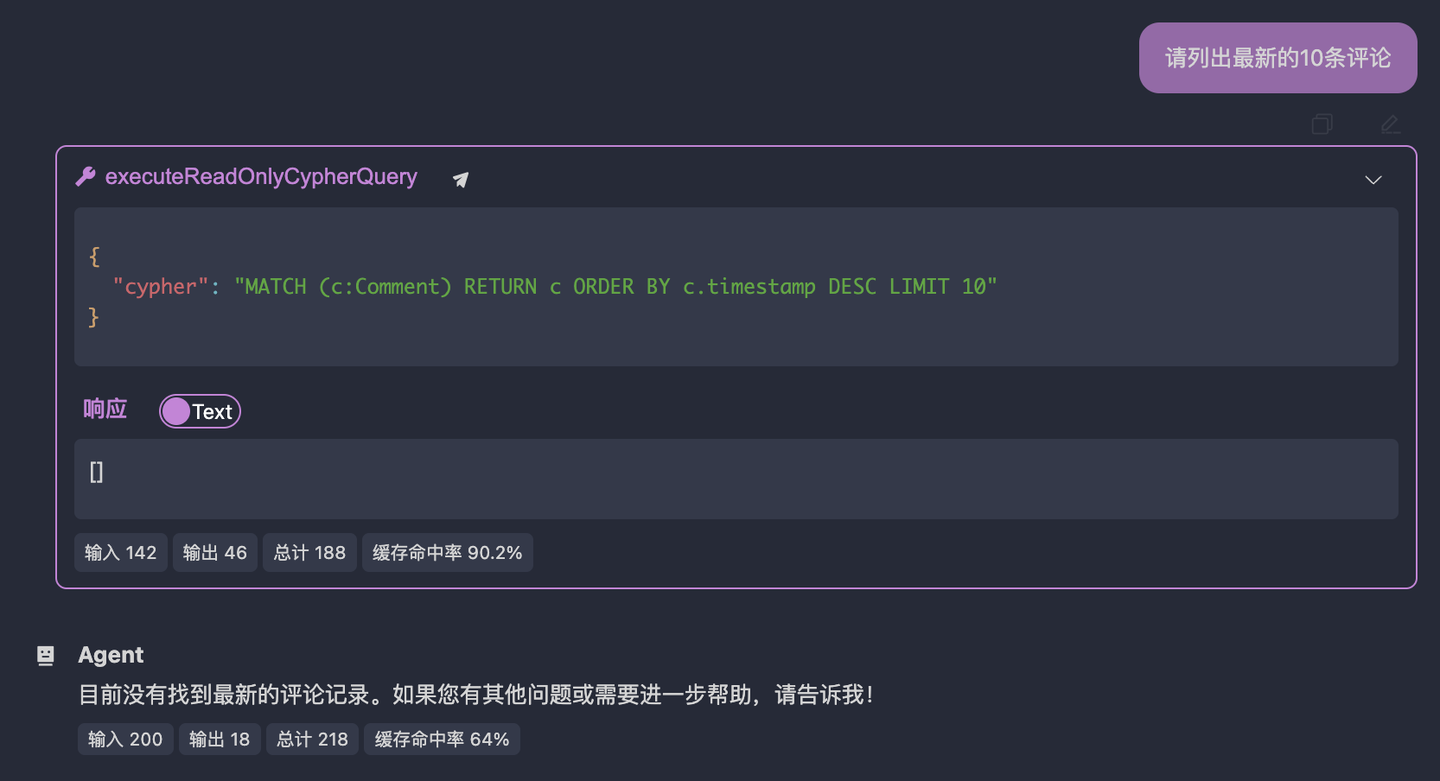
可以看到,大模型查询的节点类型就是错误的,在我提供的例子中,代表评论的节点是 BlogComment,而不是 Comment。也就是说,大模型并不掌握进行数据库查询的通用方法论。这就是我们目前知道的它的能力边界。我们接下来要一步一步地注入我们的经验和知识,唔姆,通过 system prompt 来完成。
4.4 教大模型找数据库节点
好好想一下,作为工程师的我们是怎么知道评论的节点是 BlogComment?我们一般是通过罗列当前数据库的所有节点的类型来从命名中猜测的,比如,对于这个数据库,我一般会先输入如下的 cypher 查询:
CALL db.labels() YIELD label RETURN label
它的输出就在 4.2 的图中,如果你的英文不错,也能看出来 BlogComment 大概率是代表博客评论的节点。好了,那么我们将这段方法论注入到 system prompt 中,从而封装我们的这层知识,点击下图的下方的按钮,进入到【系统提示词】:
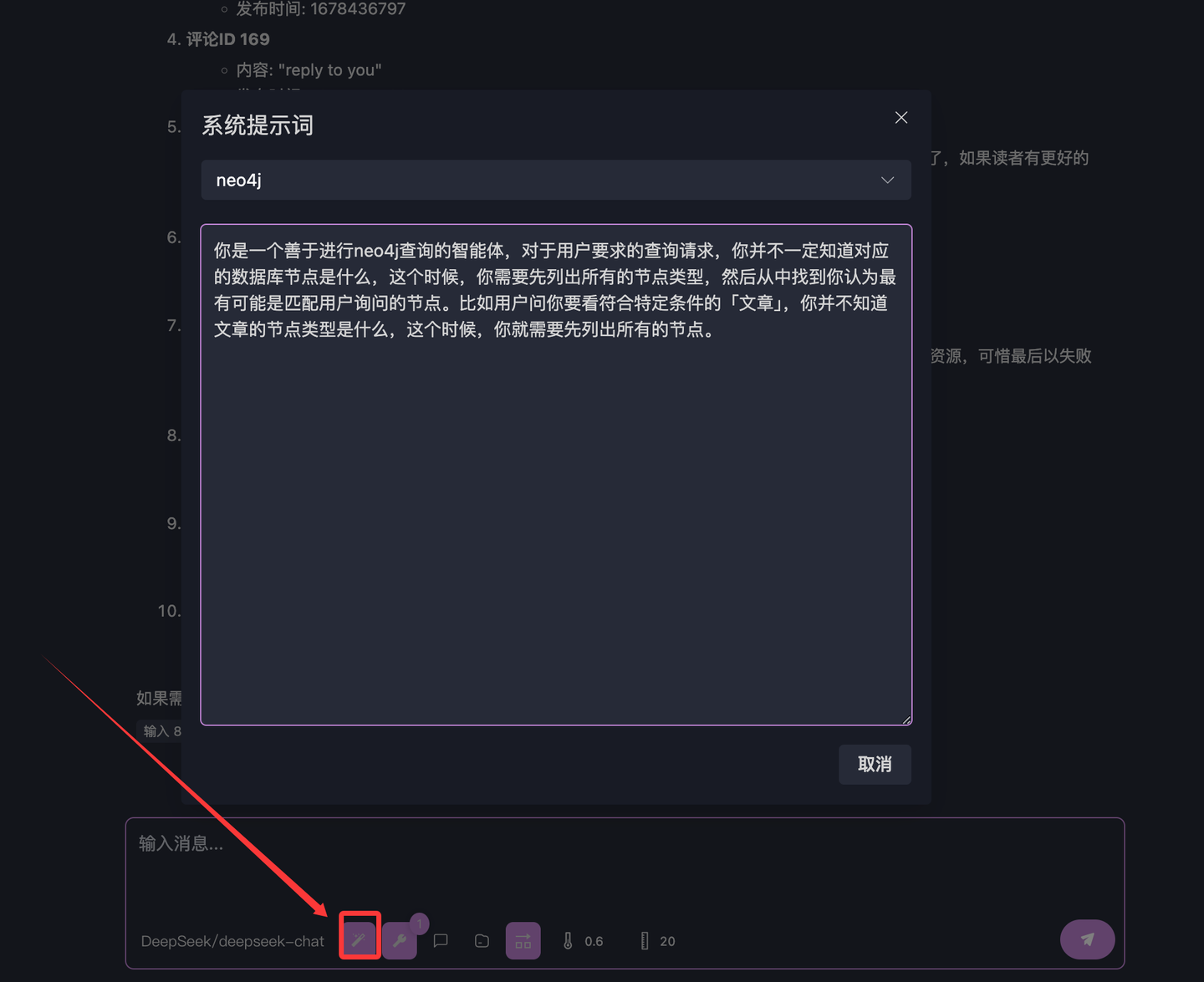
新建提示词【neo4j】,输入:
你是一个善于进行neo4j查询的智能体,对于用户要求的查询请求,你并不一定知道对应的数据库节点是什么,这个时候,你需要先列出所有的节点类型,然后从中找到你认为最有可能是匹配用户询问的节点。比如用户问你要看符合特定条件的「文章」,你并不知道文章的节点类型是什么,这个时候,你就需要先列出所有的节点。
点击保存,然后在【交互测试】中,重复刚才的问题:
帮我找出最新的 10 条评论
大模型的回答如下:
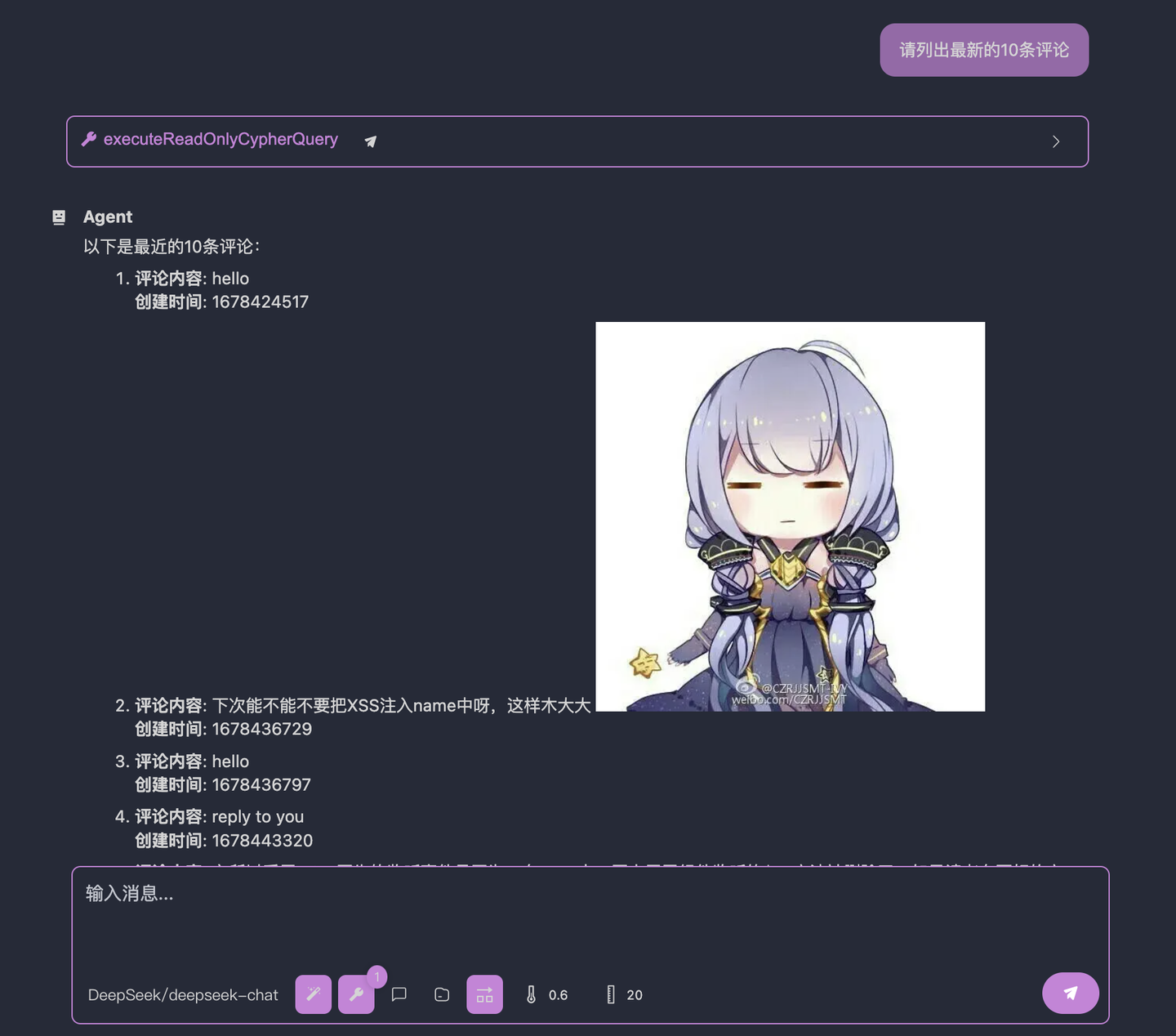
诶?怎么说,是不是好了很多了?大模型成功找到了 BlogComment 这个节点,然后返回了对应的数据。
但是其实还是不太对,因为我们要求的说最新的 10 条评论,但是大模型返回的其实是最早的 10 条评论,我们点开大模型的调用细节就能看到,大模型是通过 ORDER BY comment.createdAt 来实现的,但是问题是,在我们的数据库中,记录一条评论何时创建的字段并不是 createdAt,而是 createdTime,这意味着大模型并不知道自己不知道节点的字段,从而产生了「幻觉」,瞎输入了一个字段。
大模型是不会显式说自己不知道的,锦恢研究生关于 OOD 的一项研究可以说明这件事的本质原因:EDL(Evidential Deep Learning) 原理与代码实现,如果阁下的好奇心能够配得上您的数学功底,可以一试这篇文章。总之,阁下只需要知道,正因为大模型对自己不知道的东西会产生幻觉,所以才有我们得以注入经验的操作空间。
4.5 教大模型找数据库节点的字段
通过上面的尝试,我们知道我们距离终点只剩一点了,那就是告诉大模型,我们的数据库中,记录一条评论何时创建的字段并不是 createdAt,而是 createdTime。
对于识别字段的知识,我们改良一下刚刚的系统提示词下:
你是一个善于进行neo4j查询的智能体,对于用户要求的查询请求,你并不一定知道对应的数据库节点是什么,这个时候,你需要先列出所有的节点类型,然后从中找到你认为最有可能是匹配用户询问的节点。比如用户问你要看符合特定条件的「文章」,你并不知道文章的节点类型是什么,这个时候,你就需要先列出所有的节点。
对于比较具体的查询,你需要先查询单个事例来看一下当前类型有哪些字段。比如用户问你最新的文章,你是不知道文章节点的哪一个字段代表 「创建时间」的,因此,你需要先列出一到两个文章节点,看一下里面有什么字段,然后再创建查询查看最新的10篇文章。
结果如下:
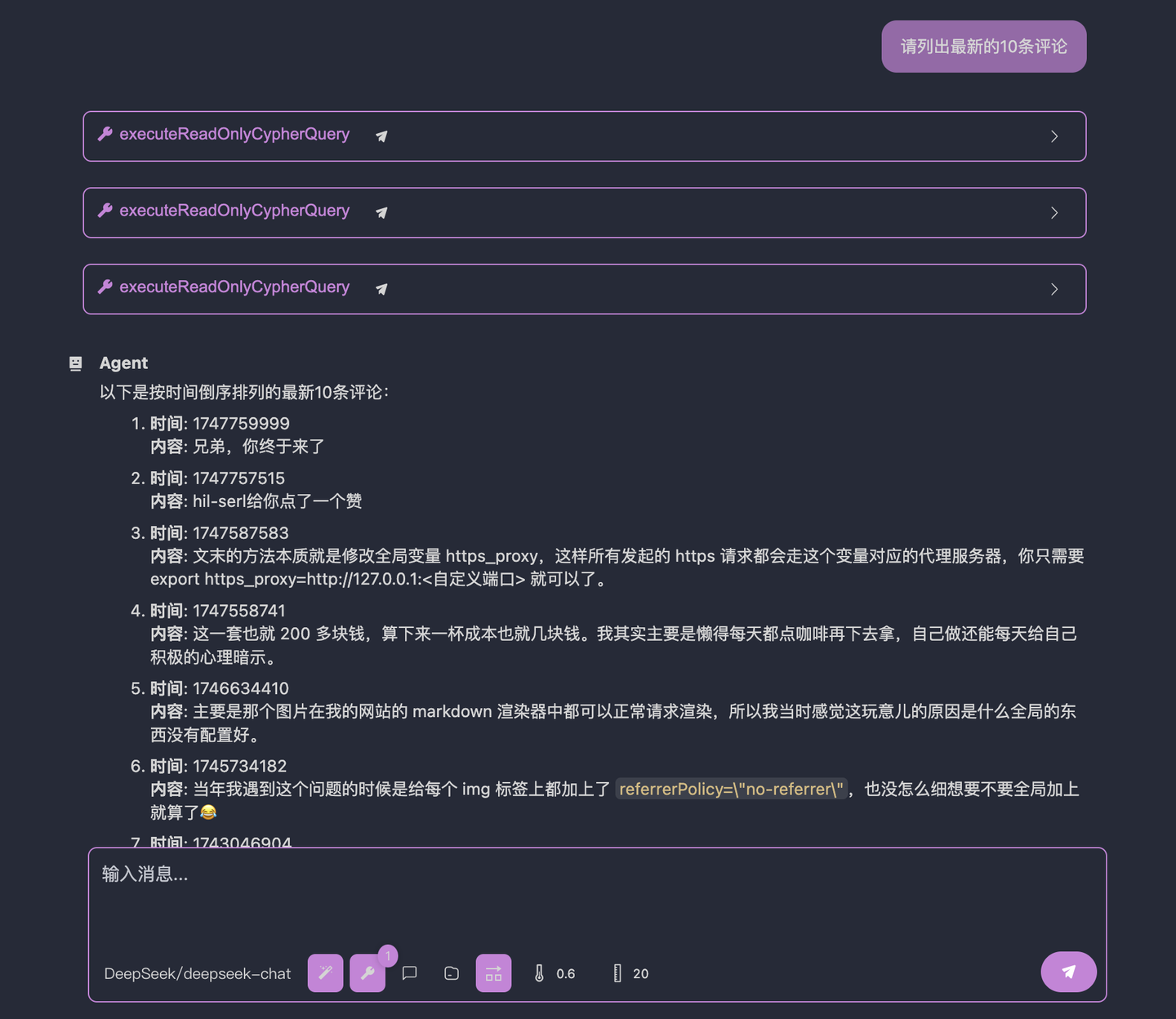
是不是很完美?
通过使用 openmcp 调试,我们可以通过 system prompt + mcp server 来唯一确定一个 agent 的表现行为。
5. 扩充 mcp 服务器的原子技能
在上面的例子中,虽然我们通过 system prompt 注入了我们的经验和知识,但是其实你会发现这些我们注入的行为,比如「查询所有节点类型」和「获取一个节点的所有字段」,是不是流程很固定?但是 system prompt 是通过自然语言编写的,它具有语言特有的模糊性,我们无法保证它一定是可以拓展的。那么除了 system prompt,还有什么方法可以注入我们的经验与知识呢?有的,兄弟,有的。
在这种流程固定,而且这个操作也非常地容易让「稍微有点经验的人」也能想到的情况下,除了使用 system prompt 外,我们还有一个方法可以做到更加标准化地注入知识,也就是把上面的这些个流程写成额外的 mcp tool。这个方法被我称为「原子化扩充」(Atomization Supplement)。
所谓原子化扩充,也就是增加额外的 mcp tool,这些 tool 在功能层面是「原子化」的。
满足如下条件之一的 tool,被称为 原子 tool (Atomic Tool): tool 无法由更加细粒度的功能通过有限组合得到 组成得到 tool 的更加细粒度的功能,大模型并不会完全使用,或者使用不可靠 (比如汇编语言,比如 DOM 查询)
扩充额外的原子 tool,能够让大模型知道 “啊!我还有别的手段可以耍!” ,那么只要 description 比较恰当,大模型就能够使用它们来获得额外的信息,而不是产生「幻觉」让任务失败。
对于上面的一整套流程,我们目前知道了如下两个技能大模型是会产生「幻觉」的:
- 获取一个节点类别的标签(询问评论,大模型没说自己不知道什么是评论标签,而是直接使用了 Comment,但是实际的评论标签是 BlogComment)
- 获取一个节点类别的字段(询问最新评论,大模型选择通过 createAt 排序,但是记录 BlogComment 创建时间的字段是 createTime)
在之前,我们通过了 system prompt 来完成了信息的注入,现在,丢弃你的 system prompt 吧!我们来玩点更加有趣的游戏。在刚刚的 util.go 中,我们针对上面的两个幻觉,实现两个额外的函数 (经过测试,cursor或者trae能完美生成下面的代码,可以不用自己写):
// 获取所有的节点类型
func GetAllNodeTypes() ([]string, error) {
cypher := "MATCH (n) RETURN DISTINCT labels(n) AS labels"
result, err := ExecuteReadOnlyCypherQuery(cypher)
if err!= nil {
return nil, err
}
var nodeTypes []string
for _, record := range result {
labels := record["labels"].([]any)
for _, label := range labels {
nodeTypes = append(nodeTypes, label.(string))
}
}
return nodeTypes, nil
}
// 获取一个节点的字段示范
func GetNodeFields(nodeType string) ([]string, error) {
cypher := fmt.Sprintf("MATCH (n:%s) RETURN keys(n) AS keys LIMIT 1", nodeType)
result, err := ExecuteReadOnlyCypherQuery(cypher)
if err!= nil {
return nil, err
}
var fields []string
for _, record := range result {
keys := record["keys"].([]any)
for _, key := range keys {
fields = append(fields, key.(string))
}
}
return fields, nil
}
在 main.go 中完成它们的 schema 的申明和 tool 的注册:
// ... existing code ...
getAllNodeTypes := mcp.NewTool("getAllNodeTypes",
mcp.WithDescription("获取所有的节点类型"),
)
getNodeField := mcp.NewTool("getNodeField",
mcp.WithDescription("获取节点的字段"),
mcp.WithString("nodeLabel",
mcp.Required(),
mcp.Description("节点的标签"),
),
)
// 注册对应的工具到 schema 上
s.AddTool(getAllNodeTypes, func(ctx context.Context, request mcp.CallToolRequest) (*mcp.CallToolResult, error) {
result, err := util.GetAllNodeTypes()
fmt.Println(result)
if err != nil {
return mcp.NewToolResultText(""), err
}
return mcp.NewToolResultText(fmt.Sprintf("%v", result)), nil
})
s.AddTool(getNodeField, func(ctx context.Context, request mcp.CallToolRequest) (*mcp.CallToolResult, error) {
nodeLabel := request.Params.Arguments["nodeLabel"].(string)
result, err := util.GetNodeFields(nodeLabel)
fmt.Println(result)
if err!= nil {
return mcp.NewToolResultText(""), err
}
return mcp.NewToolResultText(fmt.Sprintf("%v", result)), nil
})
// ... existing code ...
重新运行 sse 服务器,然后直接询问大模型,此时,我们取消使用 system prompt(创建一个空的,或者直接把当前的 prompt 删除),询问结果如下:
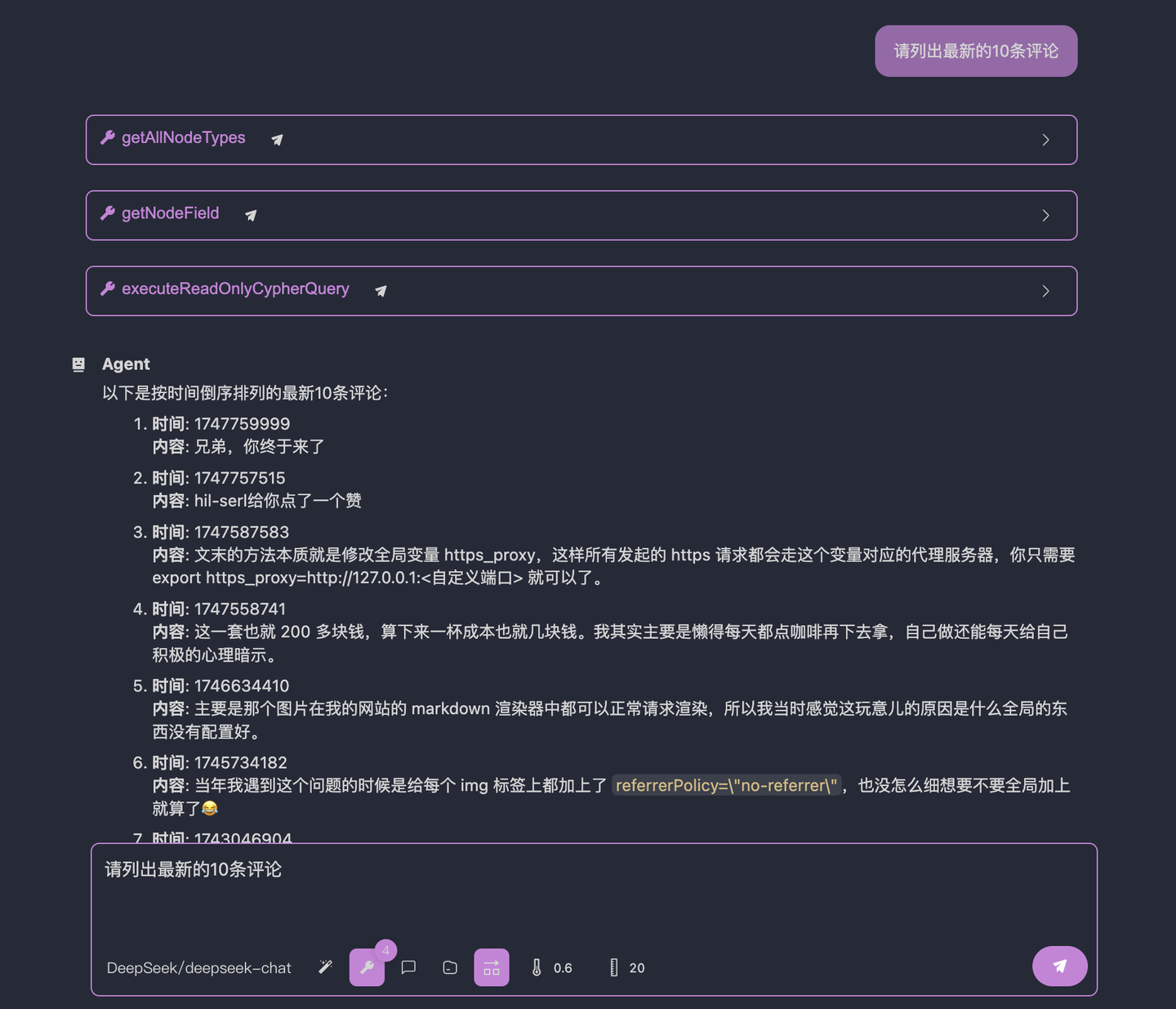
可以看到,在没有 system prompt 的情况下,大模型成功执行了这个过程,非常完美。
总结
这期教程,带大家使用 go 走完了 mcp sse 的连接方式,并且做出了一个「只读 neo4j 数据库」的 mcp,通过这个 mcp,我们可以非常方便地用自然语言查询数据库的结果,而不需要手动输入 cypher。
对于部分情况下,大模型因为「幻觉」问题而导致的任务失败,我们通过一步步有逻辑可遵循的方法论,完成了 system prompt 的调优和知识的封装。最终,通过范式化的原子化扩充的方式,将这些知识包装成了更加完善的 mcp 服务器。这样,任何人都可以直接使用你的 mcp 服务器来完成 neo4j 数据库的自然语言查询了。
最后,觉得 openmcp 好用的米娜桑,别忘了给我们的项目点个 star:https://github.com/LSTM-Kirigaya/openmcp-client
想要和我进一步交流 OpenMCP 的朋友,可以进入我们的交流群(github 项目里面有)